
| 資訊處理流程 | 生成 | 收集 | 儲存 | 使用 |
|---|---|---|---|---|
| Prometheus Client Library | ✓ | |||
| Exporter | ✓ | |||
| Prometheus Server | ✓ | ✓ | ✓ |
Prometheus 是一個廣受歡迎的監控和告警工具,主要用於收集和處理指標(Metrics)。它源於 2012 年音樂分享平台 SoundCloud 的內部需求,當時該公司正面臨管理數百個微服務和數千個 Process 的巨大挑戰,要知道那是個 Docker(2013 發布) 與 Kubernetes(2014 發布) 都還沒有發布的年代。為了應對這些複雜性,SoundCloud 決定開發一個全新的監控解決方案,以替代當時使用的 StatsD 和 Graphite。

在這個背景下,Prometheus 誕生了。它不僅能夠高效地處理大量的指標數據,還具有靈活的查詢語言和多樣的告警選項。SoundCloud 在專案成立的第一天就將 Prometheus 開源,與社群共同灌溉了三年後,在 2015 年發布了一篇 Blog 文章,詳細介紹了如何使用 Prometheus。這篇文章迅速引起了廣泛關注,甚至在 Hacker News 上被推到了第一名。
另一個令 Prometheus 嶄露頭角的時刻是 Kubernetes 的崛起。Kubernetes 在一開始就選擇了 Prometheus 作為其標配的監控工具,這大大增加了 Prometheus 的可見度和使用率。而與 Kubernetes 緊密的合作關係也讓 Prometheus 在 2016 年加入 CNCF,成為該組織下的第二個專案,自此 Prometheus 成為了指標監控的業界標準。
Prometheus 的名稱源自於希臘神話中的泰坦神 Prometheus,因為幫凡人竊取了火種而被宙斯懲罰。Prometheus 的 Logo — 一把火炬,就源自於被竊取的火苗。而「Prometheus」這個字也有「先見之明」的涵義;這與指標與監控的意象相當符合。透過指標,問題可以在微小的階段就被及早發現,避免進一步擴大。
Prometheus 之所以能具有如此巨大的影響力,是因為多年來,社群已經建立了許多工具以協助產出 Prometheus Metrics。例如,不同語言的程式可以透過 Prometheus Client Library 或是開源套件來生成和揭露指標,如在 Lab 中示範的 Python FastAPI 使用了 Prometheus Client Library,而 Java Spring Boot 則是利用其本身的 Actuator 機制搭配 Micrometer。此外,也有針對特定機器或服務撰寫的 Exporter,能採集目標上的資訊,然後將其轉譯為 Prometheus Metrics 並揭露。
Prometheus Server 負責爬取 Prometheus Metrics,並將其儲存至自己本地端的 Time Series DB(因此有時候也有人會將 Prometheus 稱為一個 Time Series DB)。該服務也提供了 Web UI,用於使用 PromQL 語法查詢收集來的 Metrics;外部服務也可透過 API 使用 PromQL 進行查詢。
在收集到各種指標後,自然不可能一直有人盯著畫面進行查詢,以檢查是否超過了閾值(Threshold)。因此,Prometheus 提供了告警機制,分為兩個主要部分:
Prometheus Server 會根據設定檔中的 scrape_configs 負責爬取 Prometheus Metrics。設定格式與常用參數如下:
scrape_configs:
- job_name: "prometheus" # Job 名稱;收集到的 Metrics 會增加 job=job_name 的 Label
scrape_interval: 15s # 定期爬取的週期,預設會繼承 global 設定的 scrape_interval
metrics_path: "/metrics" # 要爬取的 Metrics 的 Path,預設為 /metrics
static_configs:
- targets: ["localhost:9090"] # 要爬取的機器清單,預設使用 http
以上這筆設定用於爬取 Prometheus Server 自己提供的 Prometheus Metrics,會定期每 15 秒爬取一次 localhost:9090/metrics。採集到的 Metrics 會加上 job=prometheus 的 Label。此組 Scrape Job 設定適用於 Lab 的 Prometheus,可先查看 localhost:9090/metrics 的原始指標樣貌,再至 localhost:9090 使用 PromQL {job="prometheus"} 查詢收集後的指標。
在 Prometheus Web UI 的 Status 選單中提供了多種用於查看 Prometheus Server 資訊的頁面,其中兩項特別用於快速排查指標爬取問題:
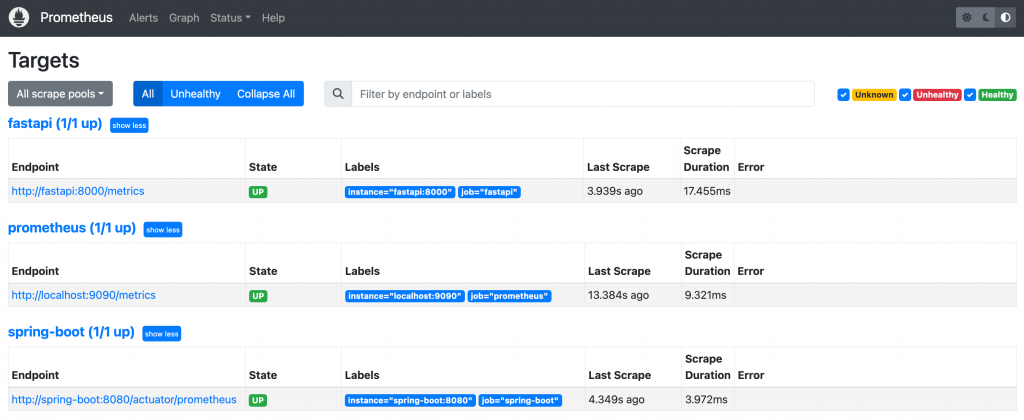
Prometheus Web UI Targets 畫面
Prometheus Metrics 主要包括四種類型:Counter、Gauge、Histogram 和 Summary。通常,提供 Prometheus Metrics 的服務會在指標上添加描述和指明類型。

Java Spring Boot Application 的 Prometheus Metric 中的四種 Metrics
_total 作為後綴。注意:數值可能會因服務重啟而歸零。<basename>_bucket{le=”<upper inclusive bound>”}
request_process_time_bucket{le=”0.1”} 5
request_process_time_bucket{le=”0.5”} 15
request_process_time_bucket{le=”+Inf”} 30
request_process_time_sum 20.5
<basename>_count,值會與 <basename>_bucket{le=”+Inf”} 相同
request_process_time_count 30
request_process_time 為例:
request_process_time_bucket{quantile=”0.5”} 0.2
request_process_time_bucket{quantile=”0.95”} 1.2
request_process_time_bucket{quantile=”0.99”} 2.0
request_process_time_sum 20.5
request_process_time_count 30
雖然 Counter 和 Gauge 很容易理解和區分,但 Histogram 和 Summary 在功能上有所重疊。實務上,可以考慮根據以下因素來選擇:
Prometheus 採用了專門的查詢語言,稱為 PromQL(Prometheus Query Language),用以查詢各種監控指標。
首先,我們先回顧一個 Prometheus 指標的範例:
prometheus_http_requests_total{code="302",handler="/"} 3
前面的 prometheus_http_requests_total 是指標名稱(Metrics Name),大括號內的 Key-Value Pair 稱為標籤(Label),最後的數字則為這個指標搭配這組 Label 的值。這個指標可以在 Prometheus Server 的 /metrics 路徑下查到,表示 Prometheus Server 總共對 / 路徑的 HTTP 請求返回了 HTTP Status Code 302 3 次。
要查詢這個指標中所有的 HTTP Status Code 和 handler,你只需在 PromQL 中輸入該指標名稱:
prometheus_http_requests_total
Prometheus Server 會返回該指標中所有 Label 的數據。
如果你只對特定的 handler 感興趣,可以加上標籤的篩選條件。例如,要篩選 handler 為 / 的數據:
prometheus_http_requests_total{handler="/"}
這樣,Prometheus Server 會返回 handler 為 / ,但 HTTP Status Code 為不同值的數據。
使用這種指標和標籤篩選的方式是 PromQL 最基礎的查詢方法。但其實也可以只篩選標籤不篩選指標名稱,例如,要查看 prometheus 這個 Job 收集了哪些指標,你可以使用:
{job="prometheus"}
除了基本的等於 = 篩選外,你還可以使用不等於 !=,或者符合正規表示式 =~ 和不符合正規表示式 !~。例如:
prometheus_http_requests_total{code=~"2.*"}
篩選出 Code 為 2 開頭的指標數據
prometheus_http_requests_total{code!~"2.*"}
篩選出 Code 不為 2 開頭的指標數據
前面所舉的查詢結果都是瞬時向量,是某個指定時間點的指標值。在 Prometheus Web UI 查詢時,如果沒有指定時間,就是查詢當下的時間點,即最新的指標值。
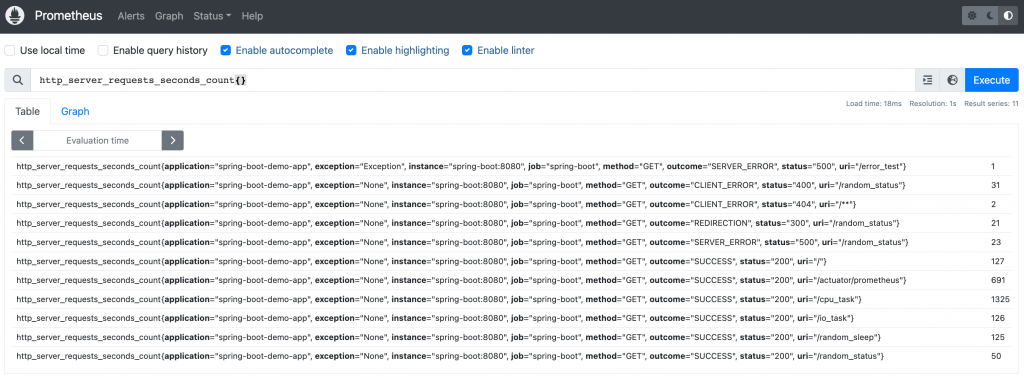
瞬時向量在 Table 中的樣子
當查詢一個時間區間內的所有瞬時向量的結果,就可以被繪製成圖表。
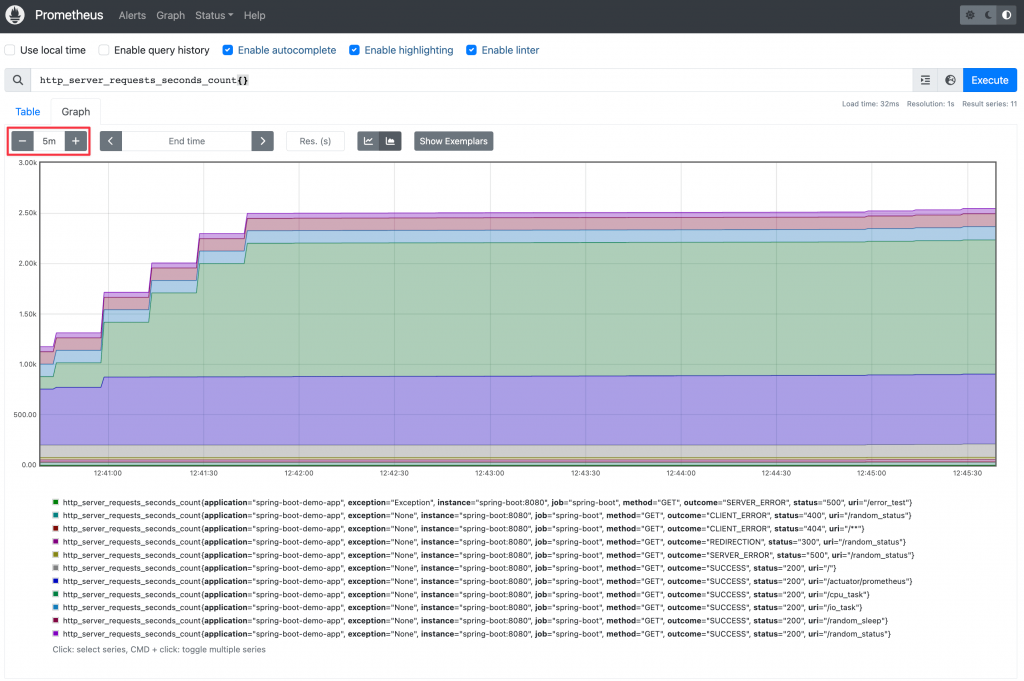
注意左上角框選的 5m,表示查詢了 5 分鐘內的所有瞬時向量,所以能夠繪製成圖表
了解瞬時向量一次只會查詢到一個時間點的數據後,再來理解區間向量會比較清楚。區間向量指的是查詢某個時間點前的一段時間的數據;語法為後面瞬時向量的查詢語法後加上中括號與時間。例如:http_server_requests_seconds_count{}[3m] 表示要查詢指定時間點前三分鐘內的所有值。區間向量於 Web UI 查詢的結果如下圖:
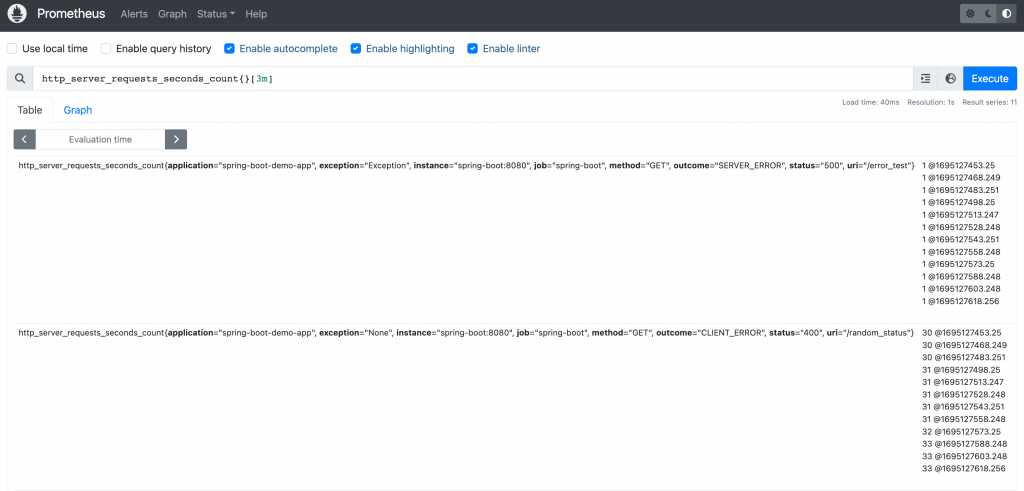
區間向量在 Table 中的樣子,每個指標都回傳了多筆數據,@ 前為指標值,@ 後為 Unix timestamp
可以看到查詢結果有多組值。這時如果切換到 Graph 會發現出現錯誤提示:「Error executing query: invalid parameter "query": invalid expression type "range vector" for range query, must be Scalar or instant Vector」。這是因為圖表是同時查詢多個時間點,區間向量本身在單個時間點上就是多個值,所以無法被繪製出來。
透過 PromQL 查詢出來的結果可以再搭配 Operator 或 Function 計算出其他結果。不過根據運算方式的特性,Operator 只能用於瞬時向量;Function 則有些可用於區間向量或瞬時向量。
其中我認為一定要了解的 Operator 與 Function 有以下四個:
sum(metrics{}) by(label_key) 或是 sum by(label_key) (metrics{}) 兩者是相同的
sum(logback_events_total{application=”spring-boot”}) by(application)
sum(logback_events_total{level=”debug”}) by(application) / sum(logback_events_total{}) by(application)
rate(http_server_requests_seconds_count{uri=”/”}[3m])
histogram_quantile(0.95, sum(rate(http_server_requests_seconds_bucket{uri=”/”}[3m])) by(le))
PromQL 雖然初看起來有些複雜,還區分瞬時向量與區間向量,但其實在使用時不用太過擔心,如果用錯向量種類或有語法錯誤,在 Prometheus Web UI 或 Grafana 查詢時都會有明確的錯誤提示,Grafana 甚至會提供 Function 使用建議。實務上也多會參考別人已經撰寫好的查詢語法,所以可以從實戰中學習 PromQL 即可。
範例程式碼:05-prometheus
啟動所有服務
docker-compose up -d
檢視服務
admin/admin
透過瀏覽器發送 Request
或是使用 k6 發送 Request
k6 run --vus 1 --duration 300s k6-script.js
關閉所有服務
docker-compose down
etc/prometheus/prometheus.yml 設定檔,從 FastAPI App 與 Spring Boot App 爬取 MetricsPrometheus 從一開始的小小內部專案,伴隨著社群的努力灌溉和 Kubernetes 的採用,已統領 Metrics 領域,成為事實上(de facto)的 Metrics Standard。它之所以能夠被大家推崇使用,各種搭配的工具也功不可沒。下一篇,我們將介紹有哪些 Exporter 可以將資訊轉譯成 Prometheus Metrics。

